What is CodeSage?
CodeSage is a family of source code embedding models with
a Transformer encoder architecture that support a wide range of source code understanding tasks,
and is available in three sizes: 130M (CodeSage-Small),
356M (CodeSage-Base), 1.3B (CodeSage-Large).
How is CodeSage trained?
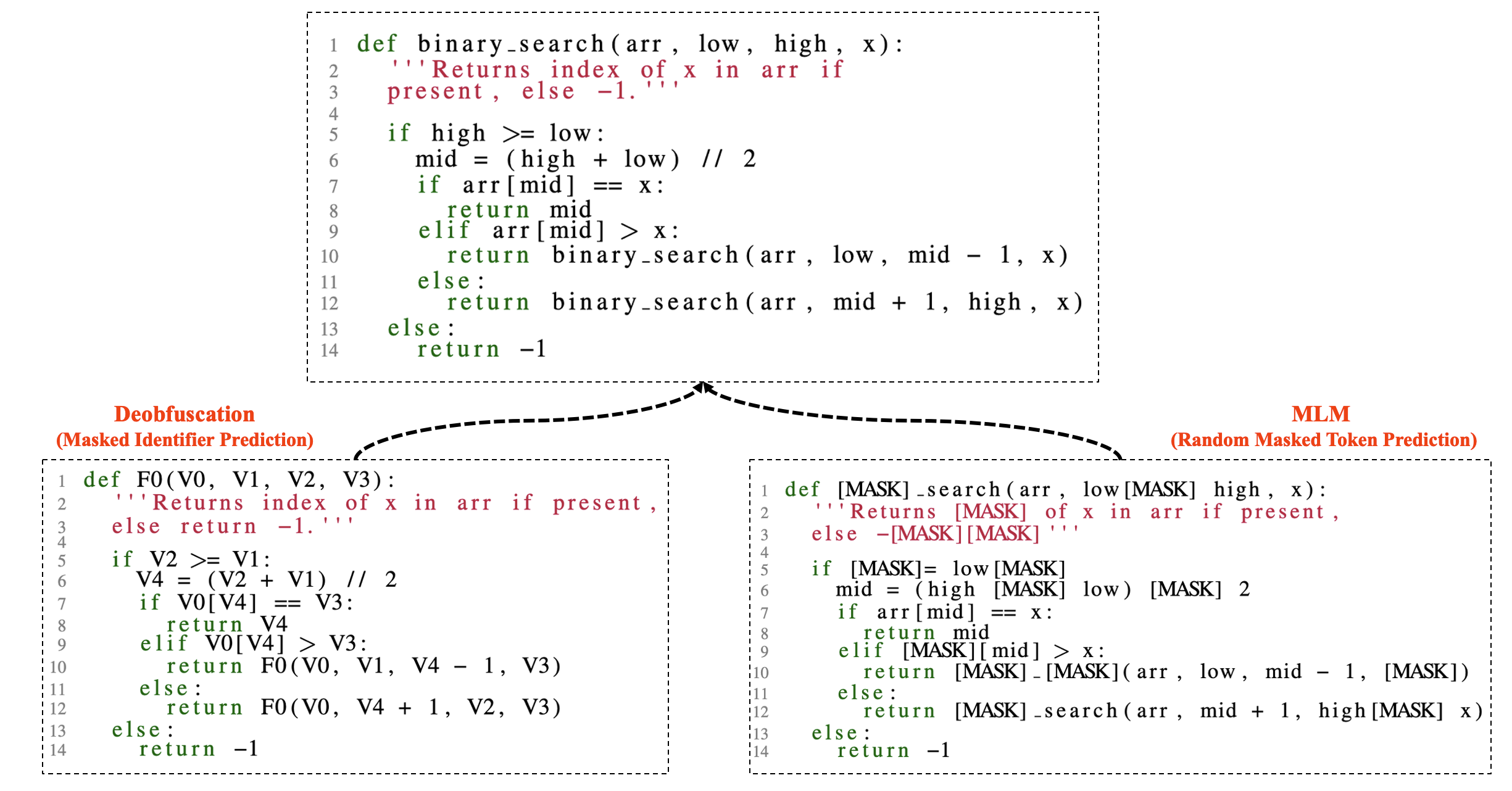
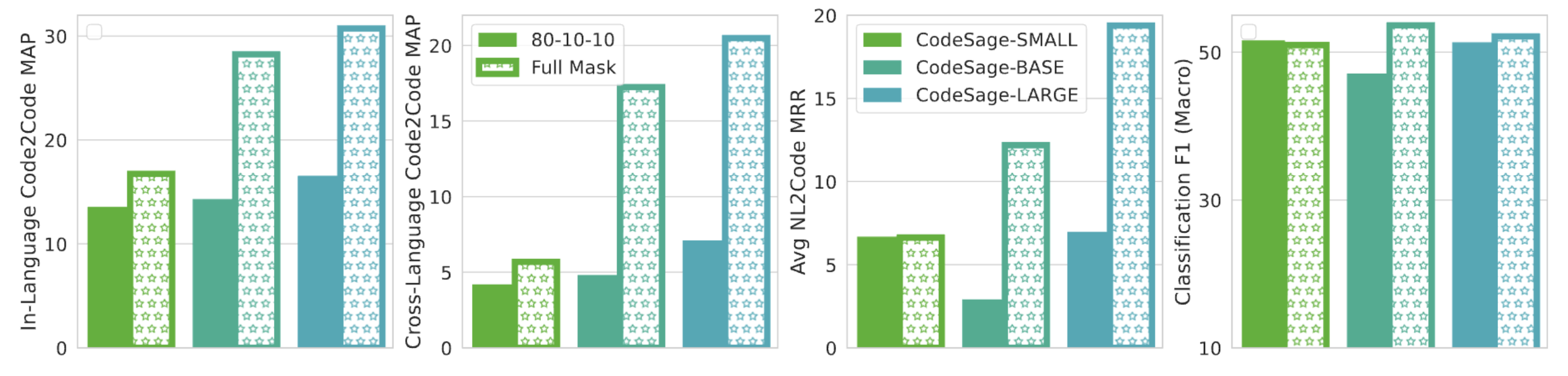
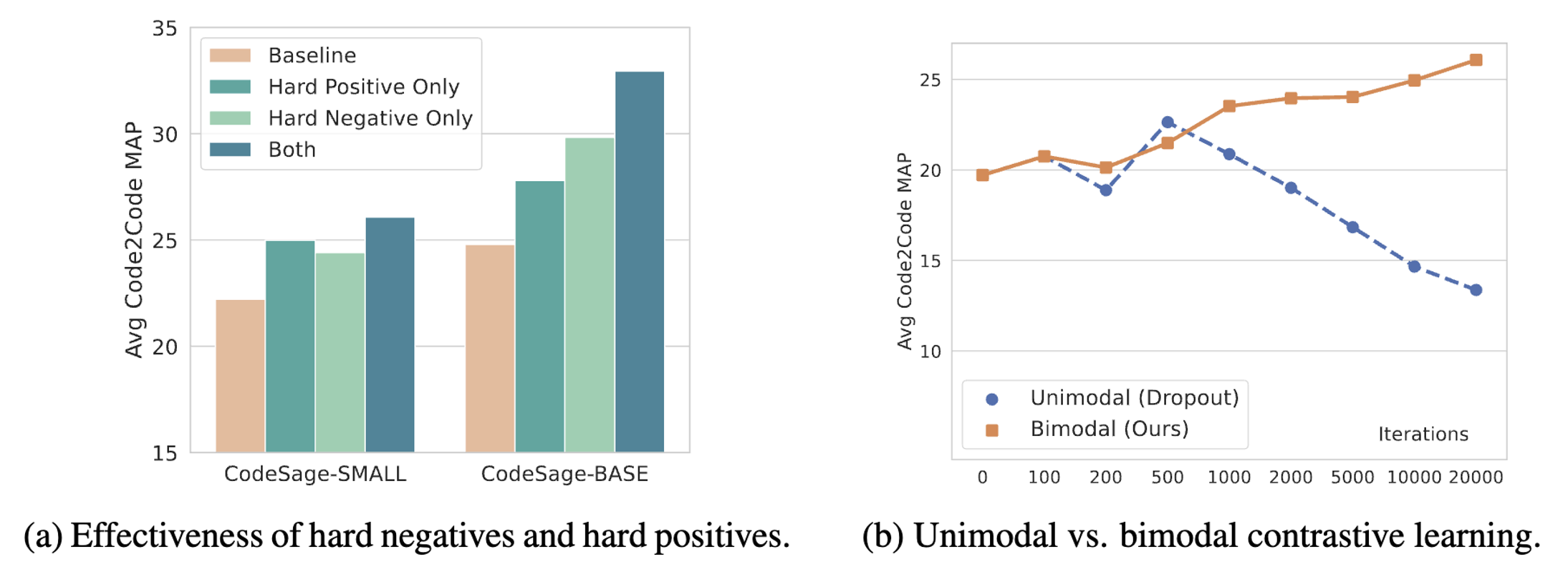
CodeSage is trained on the Stack dataset in two
stages. In stage-1, we perform masked language modeling (MLM) with a mix of standard
masking and identifier deobfuscation. In stage-2, we use contrastive learning by constructing
text-code pairs.
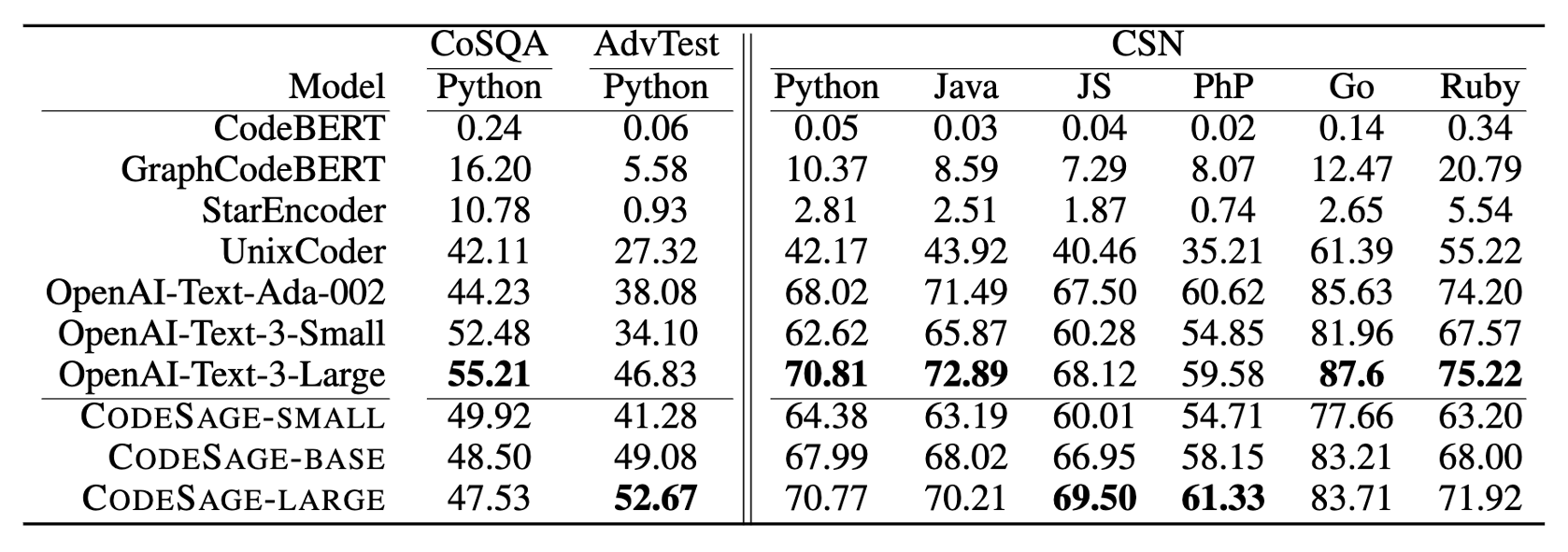
How good is CodeSage?
Our largest model, CodeSage-Large, outperforms OpenAI
text-embedding-ada-002, text-embedding-3-small, text-embedding-3-large by 41%, 144%, and 34%
(relative) respectively, on code-to-code search tasks. On text-to-code search tasks, CodeSage-Large outperforms text-embedding-ada-002,
text-embedding-3-small, and on par with text-embedding-3-large.