What is CodeSage?
CodeSage is a family of source code embedding models with
a Transformer encoder architecture that support a wide range of source code understanding tasks,
and is available in three sizes: 130M (CodeSage-Small),
356M (CodeSage-Base), 1.3B (CodeSage-Large).
How is CodeSage trained?
CodeSage is trained on the Stack dataset in two
stages. In stage-1, we perform masked language modeling (MLM) with a mix of standard
masking and identifier deobfuscation. In stage-2, we use contrastive learning by constructing
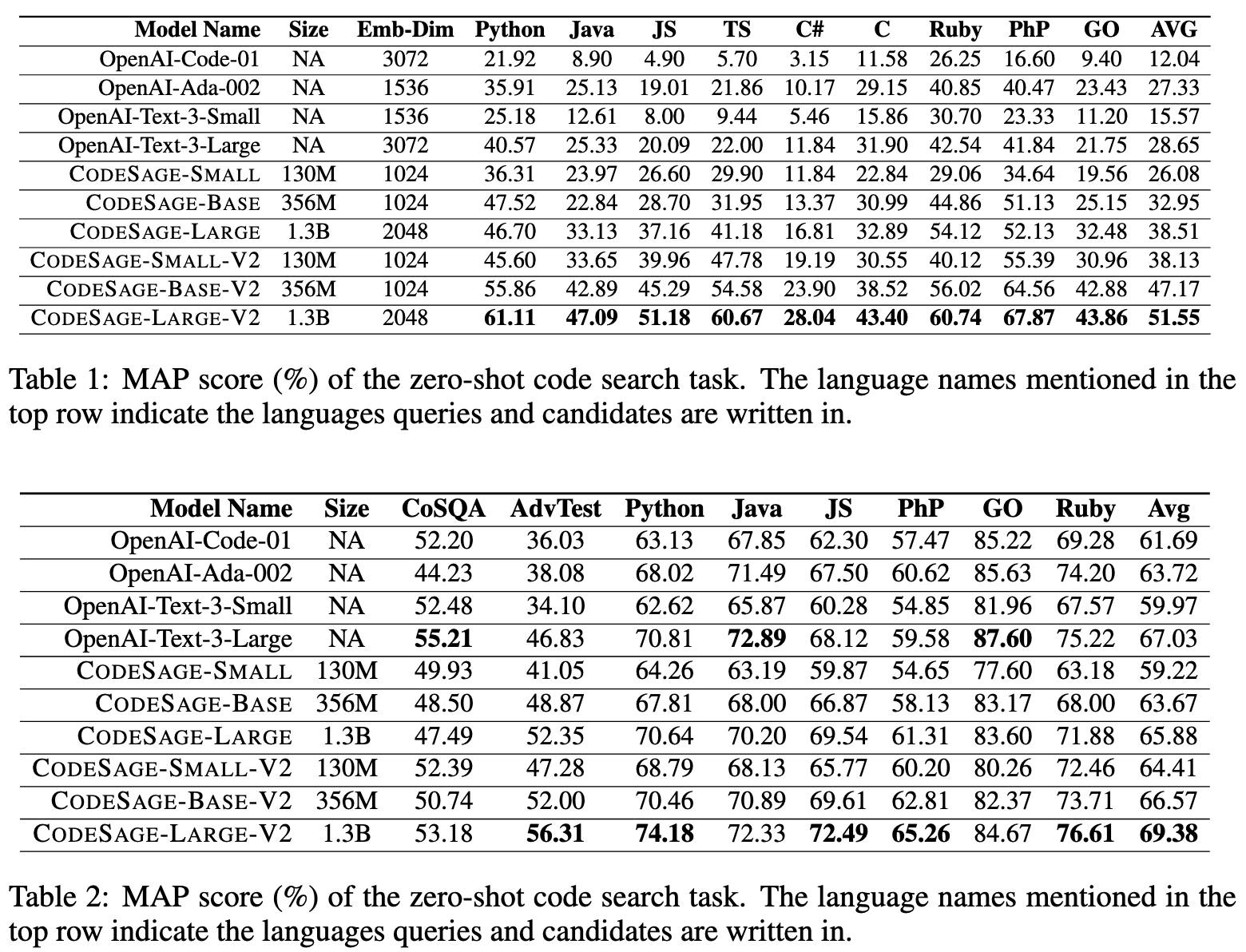
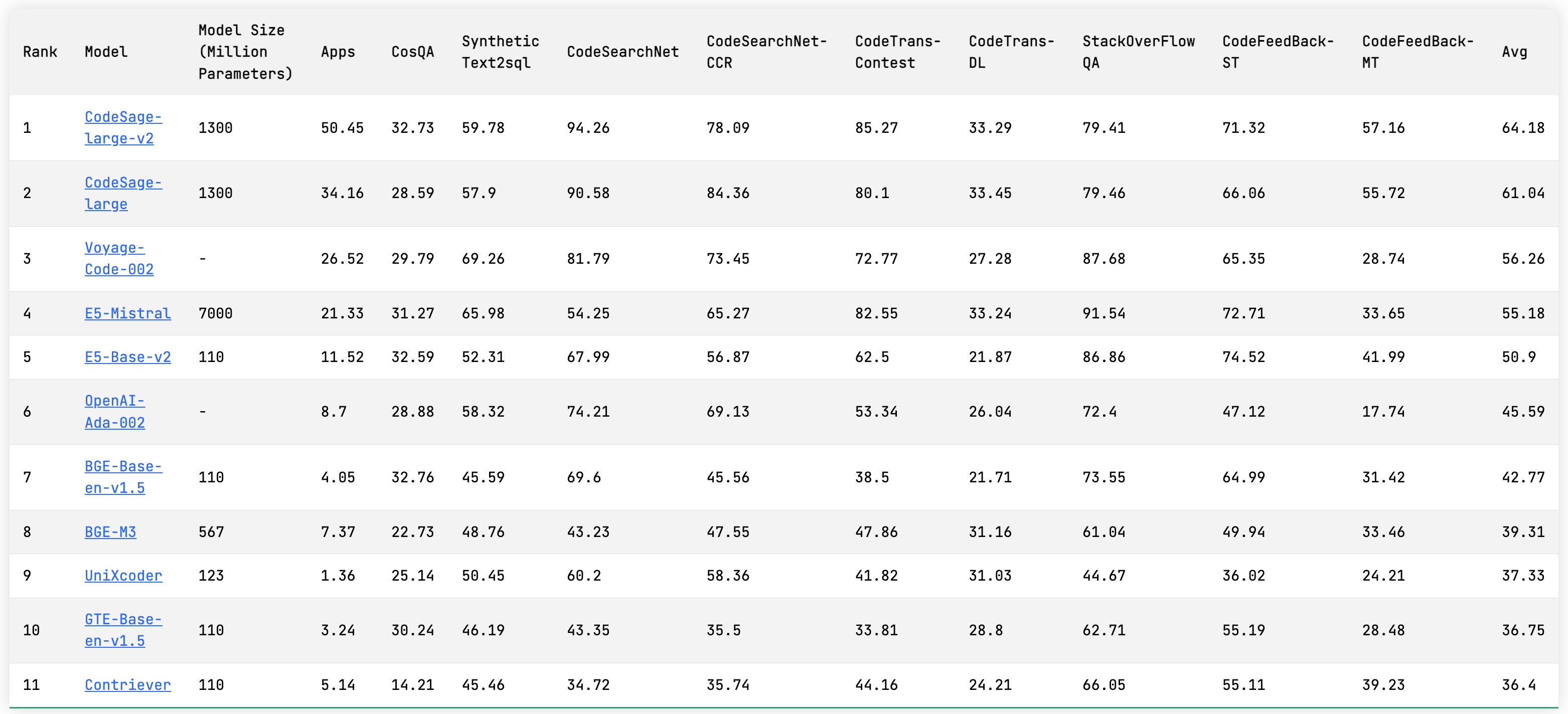
text-code pairs. Please check CodeSage-v1 for details.
What are the main differences between CodeSage-V1 and CodeSage-V2?
Flexible Embedding Dimensions. CodeSage-V2 supports flexible embedding sizes, thanks to Matryoshka Representation Learning.
Improved Retrieval Performance. CodeSage-V1 primarily relies on hand-crafted heuristics to filter the (summary, code) pairs constructed from GitHub data,
such as extracting the first sentence of a docstring as the summary and filtering out data with excessively short summaries or code snippets
(Husain et al., 2019; Zhang et al., 2024). For this V2 model, we enhanced semantic search performance by
improving the quality of the contrastive learning data through consistency filtering.
Starting from the pretrained checkpoints (trained with both Masked Language Modeling (MLM) and Deobfuscation see Section 3.1)
from our V1 model family,
we applied contrastive learning with the filtered data. Unlike the V1 model training, we extracted the initial set of (summary, code) pairs—specifically,
summaries and function/class bodies—from The Stack V2 data instead of
The Stack.
We employed simple rule-based filtering same as that used for training the V1 models.
We then applied consistency filtering to further refine the data. While using The Stack V2 resulted in minor performance boosts on downstream tasks,
the majority of the performance improvements came from the consistency filtering.
Less is More
To perform consistency filtering, we train CodeSage-Base for one epoch using the full contrastive learning dataset obtained via rule-based filtering.
Following this, we refine the data by removing any positive pairs where the similarity score is not within the top three relative to the anchor's similarity scores with 100,000
sampled examples. This process allows us to remove 40% of the contrastive learning data while yielding over a 10% absolute improvement in Code2Code search and over a 3% improvement
in NL2Code search, compared to the baselines trained without consistency filtering. These improvements are mainly attributed to the enhanced quality of the contrastive learning data, which also allow us to use a larger learning rate to elicit
better performance.